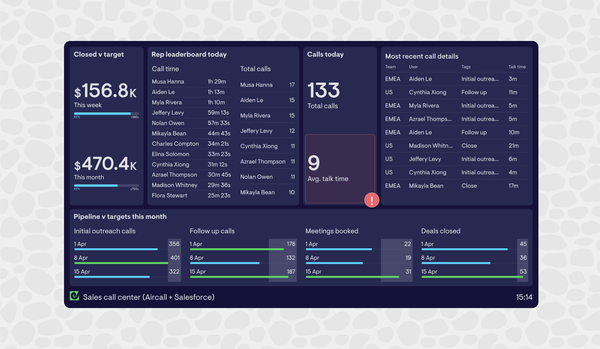
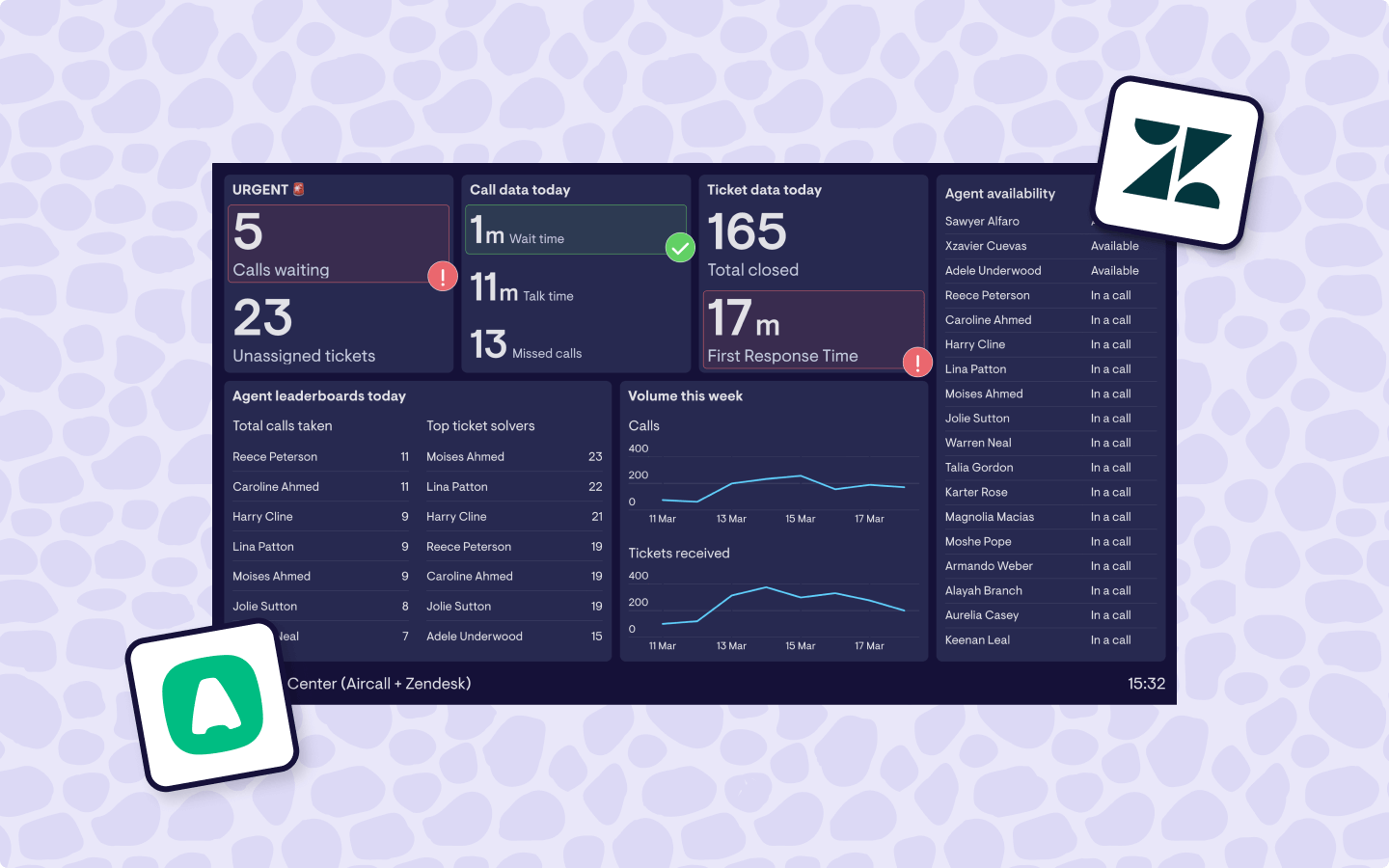
Mastering HubSpot reporting: How sales leaders can build visual dashboards that drive performance by Hannah Butcher 23 June 2025